
What Is Database index 💾
Indexing makes columns faster to query by creating pointers to where data is stored within a database. Similar to bookmarks, That can make it easy to go to a certain position in the book without going through each page!

Benefits of index
Faster lookup for results. Instead of scanning the entire table for the results, Use index structures such as B-Trees or Hash Indexes to get to your data faster. This is all about reducing the # of Disk IOs.

Indexes are good at speeding up the time it takes to search and find data in SELECT queries, but they can slow down queries to UPDATE, INSERT, or DELETE. If you have tables that you modify more often than you read the data, you may not want to use indexes for quicker searching.How indexes works
Let’s start with this example, assuming we have a table of Friends. We won’t dive into the exact query that creates that table, as It differs based on the DBMS that you are using.
| ID | Name | City |
|---|---|---|
| 1 | Alex | NY |
| 2 | Sara | LA |
| 3 | Zack | VR |
| 4 | Dave | CT |
By default primary key, Which in this case (ID) is auto-indexed, meaning that the DBMS(Database Management System) will create it automatically upon creating the table.
Building on that, We can try two simple (lookup) queries that demonstrate how the index would affect query time.
-- Lookup query with Name (Non-index)
SELECT * from Friends where Name = 'Zack'In the above example, We’re trying to lookup for the non-index column, Which will scan every single row of the table, Till it finds all rows with Name='Zack'
Full table scan usually the slowest method of scanning a table due to the heavy amount of I/O reads
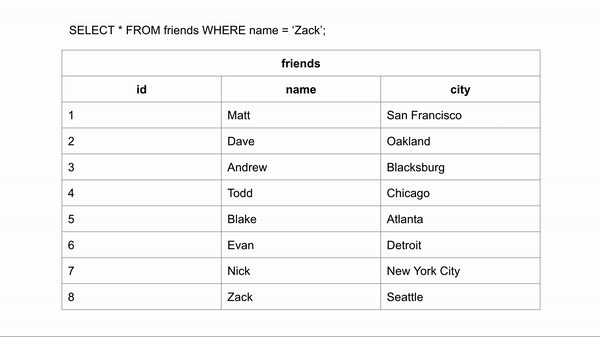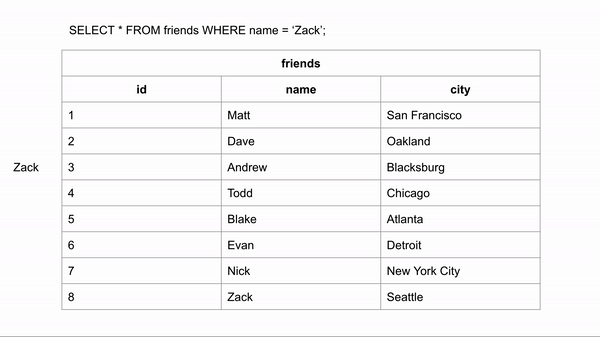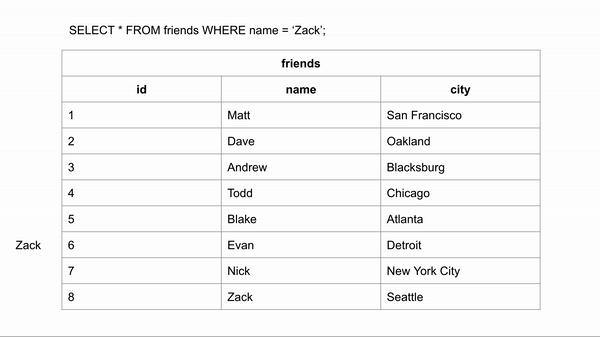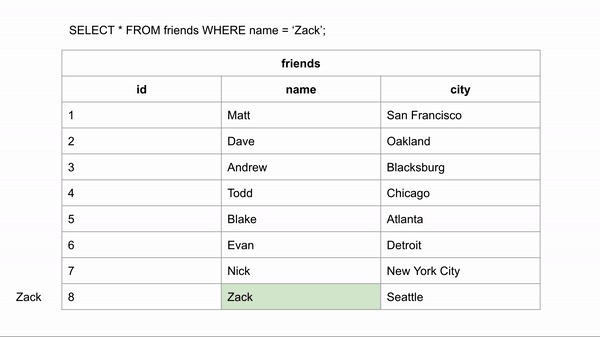
Source: Indexing
Let’s add an index and try again:
Now, we’re going to add an index to column (Name) and see how the query will be different than before.
CREATE INDEX friends_name ON Friends(Name);Once index creation is finished, We can do the same query again, but now, we should notice a significant change in # of rows that we scan.
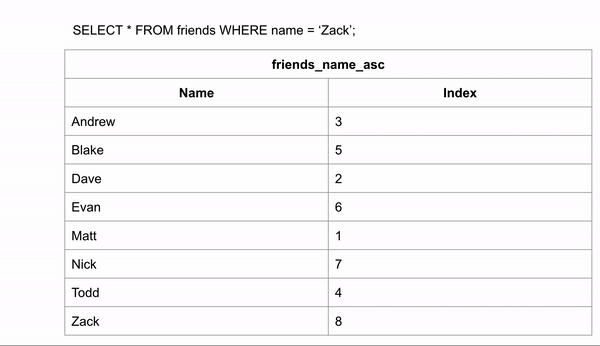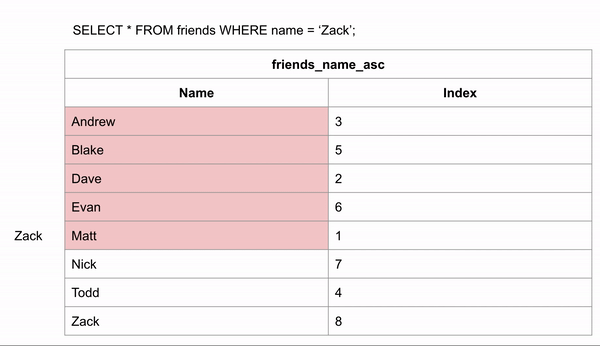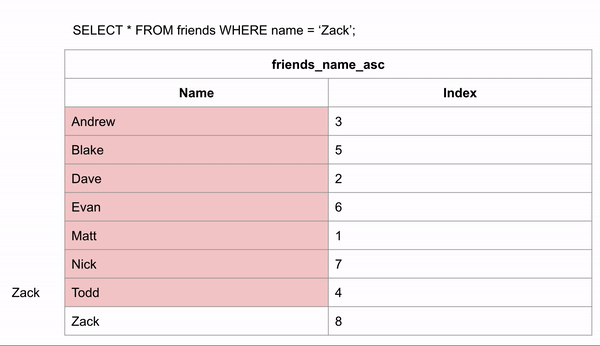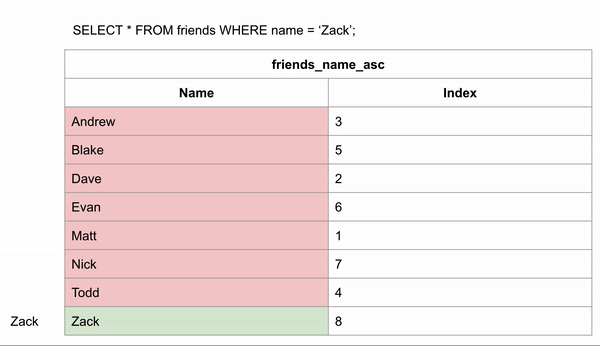
We could skip looking for the data in certain rows. If we wanted to search for "Zack" and we know the data is in alphabetical order we could jump down to halfway through the data to see if Zack comes before or after that row. We could then half the remaining rows and make the same comparison.
Source: Indexing
Indexes allow us to create sorted lists without having to create all new sorted tables, which would take up a lot of storage space. This took 3 comparisons to find the right answer instead of 9 in the unindexed data.
What is happening Under the hood?
The index will also pointers that simply reference information for the location of the additional information in memory.
With that index, the query can search for only the rows in the Name column that have Zack and then using the pointer can go into the table to find the specific row where that pointer lives.

Source: How Does Indexing Work
Types of Indexing
- Clustered index
- Non-clustered index
Both clustered and non-clustered indexes are stored and searched as B-trees, a data structure similar to a binary tree.
Clustered Indexes
A Clustered index is the type of indexing that establishes a physical sorting order of rows. Suppose you have a table Friends Table which contains ID as a primary key, then Clustered index which is self-created on that primary key will sort the Friends Table table as per ID.
- Clustered indexes do not have to be explicitly declared.
- Created when the table is created.
- Use the primary key sorted in ascending order.
Non-clustered indexes
Index is an index structure separate from the data stored in a table that reorders one or more selected columns. The non-clustered index is created to improve the performance of frequently used queries not covered by a clustered index. It’s like a textbook; the index page is created separately at the beginning of that book

And, They are used to increase the speed of queries on the table by creating columns that are more easily searchable. Non-clustered indexes can be created by data analysts/ developers after a table has been created and filled.
When Should Indexes Be Avoided?
- Small Table, It’s not effective to have indexes on a small table (Why)
- Tables that have frequent, large batch update jobs run can be indexed. However, the batch job's performance is slowed considerably by the index. The conflict of having an index on a table that is frequently loaded or manipulated by a large batch process
- Indexes should not be used on columns that contain a high number of NULL values.
- Columns that are frequently manipulated should not be indexed.
Thank you!
